The Conversion Rate Optimization Guide
Chapter 12
<<Previous | Table of Contents | Download the CRO Guide | Next >>
A/B Testing
Once you think you have determined the problem and have created a solution, the current site (the control) and the new solution (the variation) need to be tested against each other to determine which solution has a higher conversion rate.
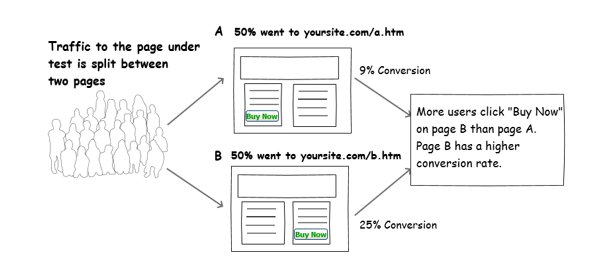
A/B testing or split testing is the process of splitting the traffic to each test page, and then analyzing the results to determine the winner with statistical confidence. The pages are tested again with other pages with the same goal. For example, the goal could be submitting the form, making a purchase or downloading a paper. This same A/B testing process should be done to your email campaigns as well.
Tip: Approach A/B testing like a scientific experiment. Only change one variable at a time for accurate results. Take detailed notes of each test and review them to learn what is working with your particular customer / user group. When creating new tests, review the old one for ideas and don’t waste time doing the same test you did last year.
After a page has been improved, you will need to review the whole conversion funnel again as well as look at your page metrics. Some changes can have effects on other parts of the site or conversion process. The conversion rate optimization process is a continual one. Sometimes a small change can make a big difference, and other times a radical overhaul to the design can create unexpected positive results.
A/B and split testing theory and statistical confidence made simple
Statistics may sound like a scary course in school but it does not have to be. Statistical confidence or statistical significance puts a percentage of accuracy for a test result. I will try to explain this without any equations so you can get the general idea.
If you had 100 visitors, 50 went to the control page A and 50 went to variation B.
If the control page had 25 conversions and the variation had 24, you can say that it is too close to call.
If the control page had 10 conversions and the variation had 20, you can say that the variation had twice as many because both had the same number of visitors.
When testing, it is rare to have an even number of testing each variation. So, extra math is needed to evaluate each test accurately. For example:
If the control had 100 visitors and 15 conversions and the variation had 80 visitors and 14 conversions, the conversion rate shows that the variation had a higher conversion rate since it has more conversions per visitor.
But how long should you test? If you remember what you learned in statistics class, you had a test with a coin landing on its head or tail. If you flipped it six times you could get more heads or more tails. However, when you flipped it 100 times the results averaged out to 50% heads and 50% tails. When testing, we want to make sure we are running enough tests to get an accurate result.
There are two factors to an accurate result: the number of tests and the difference in the results. If the results are close, then you will need to test more testers or visitors. If the results are very different then you will not need as many testers or visitors to reach statistical confidence.
Let’s assume the control conversion rate is 35 +/- 8% and the variation is 40 +/- 10%. In this case, there is an overlap in the odds of getting the same answer. If the control conversion rate is 35 +/- 5 and the variation is 50 +/- 5, then there is no overlap in the odds of getting the same conversion rate, and we can be statistically confident that the result is accurate.
In most cases, you want a statistical confidence of 90% or greater.
The actual equations for calculating the statistical confidence are looking at the ratio of the control and variation(s) conversion rates and then graphing the statistical probability that they are not going to overlap. This is graphed with different types of curves like CHI Squared and Z-Score that determines the “p” value (probability). Some A/B test systems use Bayesian calculations to make sure the tester does not take a result too early, even if it looks statistically accurate but is not because the test has not run long enough.
Calculating the statistical confidence will tell you if you need to continue testing or not. Be careful, there are some rules to follow so that you do not read your data incorrectly:
- Always test for a full week or more to get users from different time periods during a week. A Monday morning user may have a different conversion rate than a Saturday user. Some tests can run over a period of months.
- If you can graph your cumulative conversion rate over time, make sure there is a constant space between the winning variation and your control. If the lines are crisscrossing, then the test has not reached statistical confidence.
- Note that in the beginning of a test the results may seem large. For example: 1 conversion from 3 visitors is a 33% conversion rate, but in a week or two the actual result is more like 10 conversions from 300 visitors… a 3% conversion rate. Make sure you are not concluding a test with a very small number of conversions where adding one more conversion changes the conversion rate.
- If you are curious to see how “noisy” your control and testing system is or how much the conversion rate varies over time, run an A/A test. This is comparing the control against itself. Again, you have to make sure you run it long enough to see the true “noise floor.”
Testing goals
When running your first test, your typical goal is the thank you page or purchase confirmation. As you start evaluating your page under test you will start tracking multiple goals. For example, if your page has more than one call to action button, perhaps one on top and one down below, or if you have other calls to action like a “click to call” phone number or “chat.”
Tip: In some cases, having different text in the button at the bottom of the page increases the conversion rate. The last button saying “Add to Cart” and the upper buttons saying “Buy Now” for example.
Factors that affect your test
There is an endless supply of variables that can mess up your test. Ideally a clean test is with only one variable that is changing, the variation. However, there are other changes that may alter the data such that you will want to run the test longer or at a different time of year. For example:
Seasonality – Running a test over New Year’s will have a different result than during a normal work week. For some industries, summer compared to winter can have an effect. Basically, the buyer intention is different at different times of the year.
Ad traffic – Depending on the type of ads and the ads themselves, you will find different results in your control.
Competition – If the competition is running a free for three weeks’ campaign during your test, your typical control conversion rate may drop and the variation may not have an accurate lift.
Responsiveness – If your site or page is not designed well for mobile or there is a big difference in the mobile results compared to the desktop result.
Tester errors and test platform errors – If the tester stopped the test too early or if the test platform did not present the variation as you intended.
Dynamic sites or changes – If the test is not set up correctly to handle dynamic sites. Can you imagine a shopping cart that does not show what the user purchased? Another issue is a web developer changing a page under test and not letting you know about it.
<<Previous | Table of Contents | Download the CRO Guide | Next >>

- How to Add a Chatbot to Your Ecommerce Website (Step-by-Step) - June 2, 2026
- How to Use a Chatbot for Lead Generation (And Actually Get Results) - May 26, 2026
- The Rise of Intelligent Websites - February 19, 2025

